海數存HSC-CS24 高效節能的數據備份與冷存儲解決方案
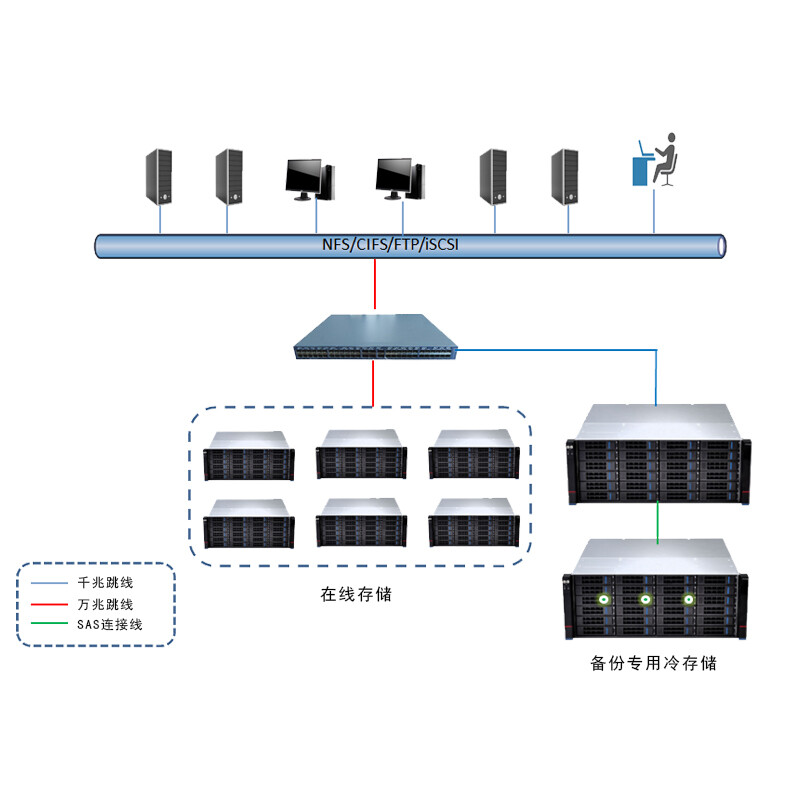
在當今數據爆炸式增長的時代,企業面臨著海量數據的存儲、備份與管理挑戰。海數存HSC-CS24備份冷存儲系統應運而生,以其創新的離線備份存儲設計,為計算機數據處理領域提供了一套節能環保、安全可靠的存儲解決方案。該系統通過數據自動分層遷移技術,智能地將活躍數據與不常訪問的冷數據區分開來,實現存儲資源的最優化配置。
海數存HSC-CS24的核心優勢在于其高效的冷數據管理能力。系統支持與離線冷盤庫、磁帶庫及光盤庫無縫對接,形成完整的數據生命周期管理體系。對于需要長期歸檔但又極少調用的數據,系統可自動將其遷移至成本更低、能耗更少的離線介質中,如磁帶或光盤,從而大幅降低總體存儲成本與能源消耗,完美契合綠色數據中心的發展理念。
在硬件配置上,該型號標配96TB的存儲容量,由24塊原廠企業級4TB硬盤組成。這些硬盤專為7x24小時不間斷運行設計,具有高可靠性、低故障率的特點,確保了數據存儲的穩定與安全。強大的硬件基礎為計算機數據處理任務,如數據分析、備份容災、歷史歸檔等,提供了堅實的性能支撐。
海數存HSC-CS24不僅僅是一個存儲設備,更是一套集智能分層、節能環保與高可靠性于一體的綜合性數據管理方案。它幫助企業在應對數據洪流的有效控制運營成本與能源支出,是構建現代化、可持續IT基礎設施的理想選擇。
如若轉載,請注明出處:http://www.dccxm.cn/product/2.html
更新時間:2026-06-19 18:12:15